Introduction
Vibe coding has become ordinary. Karpathy hasn't typed a line of code since December 2025. Coding agents like Claude Code1 1 Claude Code Overview (Anthropic, 2026) let you drive an entire development workflow from natural language: writing, debugging, testing, and even taking over your screen when GUI interaction is needed2 2 Let Claude Use Your Computer from the CLI (Anthropic, 2026) . OpenClaw3 3 OpenClaw (OpenClaw, 2026) agents manage your calendar and book flights through a chat message.
But all of this lives behind a screen. What happens when coding agents step beyond it? We believe coding agents will play an increasingly central role in the physical world. Which problems in robotics are fundamentally solvable by vibe agents, and where does that boundary lie? These are questions every roboticist will need to think about, alongside what scaffolding the task needs, what data the agent should learn from, and what harness holds it all together.
In software, when an agent fails, the failure can be folded back into the harness: a tighter constraint, a better check, and the mistake never recurs. The physical world is less forgiving, and many embodied tasks remain far beyond what today's vibe agents can reliably handle. 2026's biggest lesson in building vibe agents is that the gap between agents isn't the gap between models; it's the gap between harnesses4 4 Harness Engineering: Leveraging Codex in an Agent-First World (OpenAI, 2026) . When agents step into the physical world, the harness problem only gets harder.
This is where vibes meet gravity.
In this post, we explore two distinct interfaces through which vibe agents are showing up beyond the screen, when they work, when they don't, why the answer might not be either-or, and what it actually takes to get an agent's hands dirty.
Code as Interface
Code as interface offers two things for physical agents: composability and transparency. Embodied tasks are not single problems but chains of heterogeneous sub-problems: segmentation, grasp planning, inverse kinematics, coordinate transforms, navigation, each with its own mature tooling. Code is a natural glue for composing these tools into a coherent pipeline, with conditionals, loops, and error handling that a monolithic end-to-end policy cannot express. Transparency matters because in the physical world, understanding why an agent made a decision is not optional. When a failure occurs, code provides an auditable chain of reasoning: was it a perception error, a planning mistake, or an execution drift?
How this composition is expressed has diverged into three distinct forms. The most direct approach is to generate a complete execution flow: the code sequences perception, planning, and control calls top to bottom, much like a human engineer would write a robot script5 5 Code as Policies: Language Model Programs for Embodied Control (Liang et al., 2023) 6 6 CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation (Fu et al., 2026) . An alternative treats code not as instructions but as specifications: instead of telling the robot what to do step by step, the agent writes constraint functions or spatial value maps and lets an optimizer figure out the trajectory7 7 VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models (Huang et al., 2023) 8 8 ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation (Huang et al., 2024) . A third form accepts that code alone cannot handle everything: the agent dispatches high-level decisions through code while handing off contact-rich, low-level execution to a learned policy9 9 Gemini Robotics: Bringing AI into the Physical World (Google DeepMind, 2025) .
The natural boundary of code as interface lies in tasks that demand continuous, closed-loop feedback across multiple sensing modalities. Precision assembly requires sub-millimeter adjustments guided by force and tactile sensing at every timestep. Deformable object manipulation involves state spaces too large to plan over ahead of time. These are not problems that more turns of code generation can solve. The bottleneck is not the model's reasoning capability but the expressiveness of code as an interface: some behaviors are fundamentally continuous and resist decomposition into discrete program steps. A useful heuristic may be sim-to-real transfer: tasks where simulation faithfully captures the relevant physics tend to be tasks where coding agents can iterate, verify, and deploy with minimal gap. Where sim-to-real breaks down, code as interface usually does too.
The deeper question is what should be wrapped as an API (scaffolding) in the first place. Traditional perception and control tools like segmentation models and IK solvers are obvious candidates. Less obvious but equally important is that visuomotor policies themselves should be APIs. Just as Claude Code calls screen-level action when code alone cannot reach the task, a physical coding agent should be able to call a learned visuomotor policy when the task demands continuous, contact-rich control. VLAs can operate as standalone agents, but for a code-driven system, wrapping them as callable APIs is a natural design choice. The open questions are at the interface: what granularity should the policy expose, what should the coding agent be able to specify when invoking it, how should failures be communicated back, and how should the agent adapt when its APIs are suboptimal?
If visuomotor policies can serve as APIs within a code-driven system, action is also an interface in its own right. We have already seen significant progress in learning to act directly from perception, end to end.
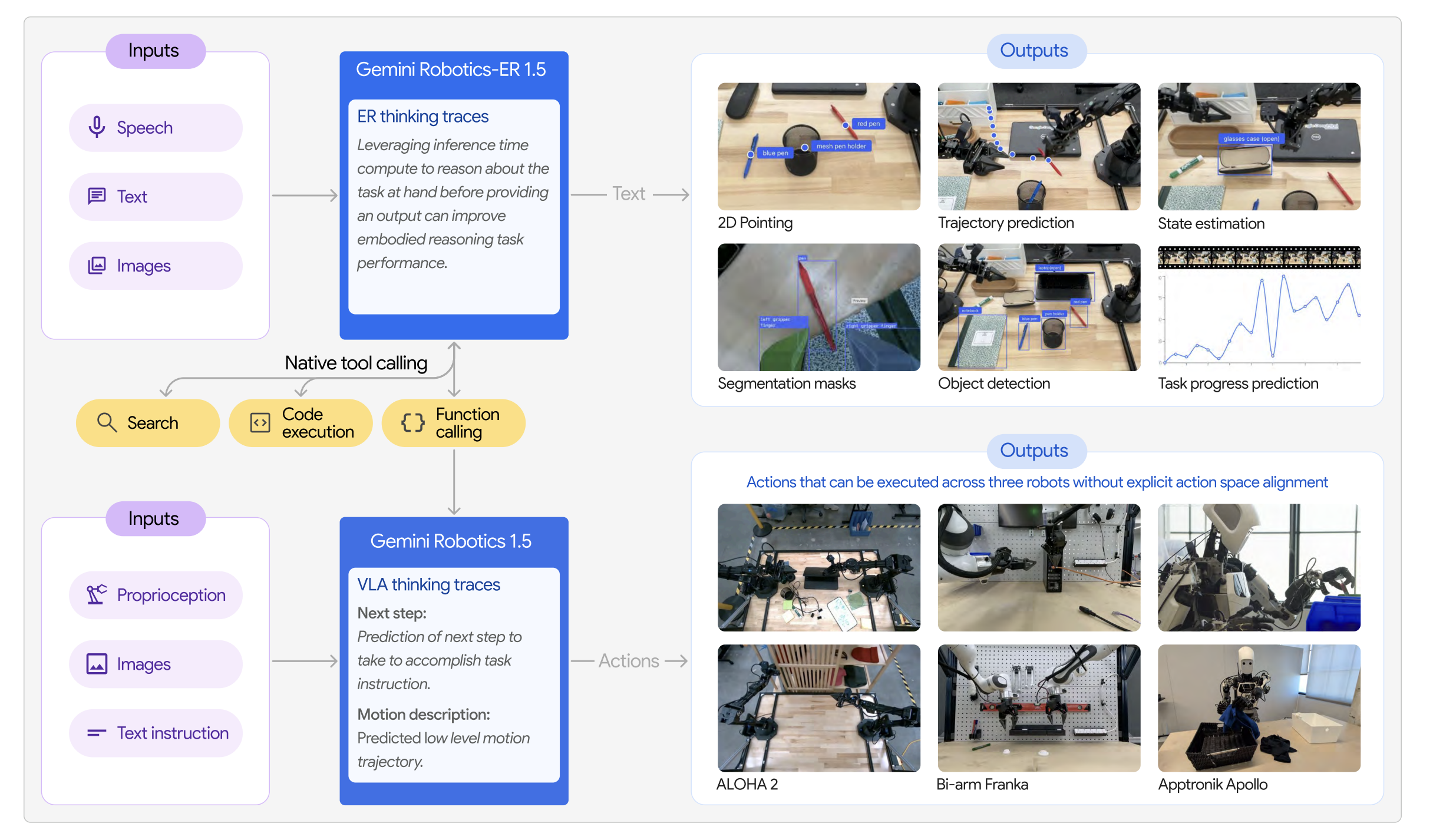
Action as Interface
Action as interface takes the opposite bet: instead of generating programs, the model directly outputs motor commands, learning continuous, contact-rich behaviors from demonstration data. Vision-language-action models like π0.5 and π*0.6 have pushed this paradigm forward, demonstrating open-world generalization, learning from on-robot experience10 10 π0.5: A VLA with Open-World Generalization (Physical Intelligence, 2025) 11 11 π*0.6: A VLA that Learns from Experience (Physical Intelligence, 2025) , and even emergent transfer from human video to robot control12 12 Emergence of Human to Robot Transfer in VLAs (Physical Intelligence, 2025) 13 13 EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos (Yang et al., 2025) 14 EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data (Zheng et al., 2026) . But these models operate within the physical world. The question of whether the same action interface can bridge digital and physical environments remains open.
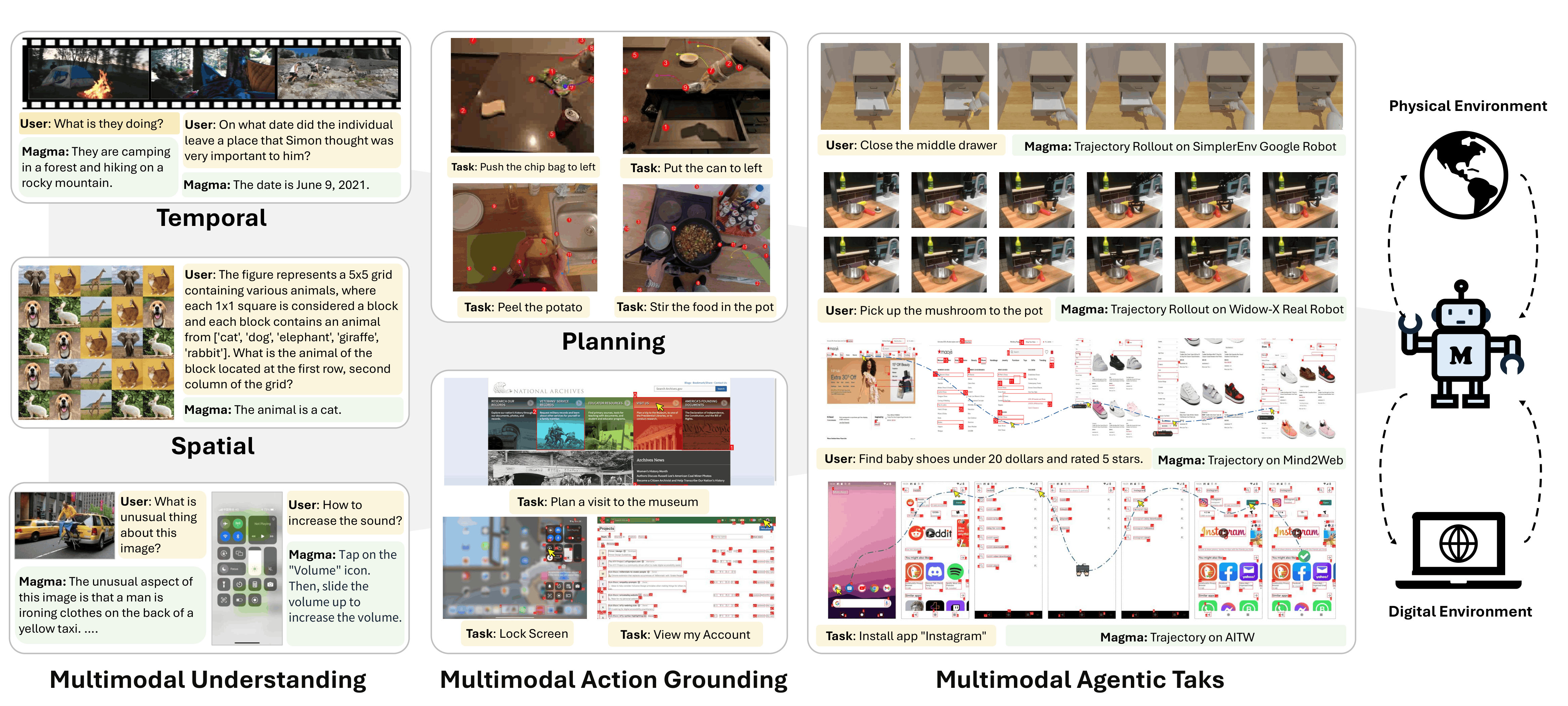
Magma starts from a different premise: agentic intelligence is not a domain-specific capability but a combination of verbal, spatial, and temporal intelligence. With freely available visual and language data, a single model can learn to plan and act across environments from phone UIs to tabletop manipulation, such as opening a robot arm's control interface on screen and then directly commanding the arm to pick up an object14 15 Magma: A Foundation Model for Multimodal AI Agents (Yang et al., 2025) . Set-of-Mark (SoM) and Trace-of-Mark (ToM) are the training objectives that make this work: SoM grounds where to act in images, ToM supervises predictions of how things move in video. Together they allow a single model to perform UI navigation, robot manipulation, and video-based planning without being trained separately for any of them. ToM's temporal intelligence also carries over to virtual agents: in GUI environments where visual trajectory prediction over screenshots is impractical, anticipatory reasoning takes the form of predicting future action sequences before executing the first step15 16 Anticipatory Planning for Multimodal AI Agents (Liang et al., 2026) .
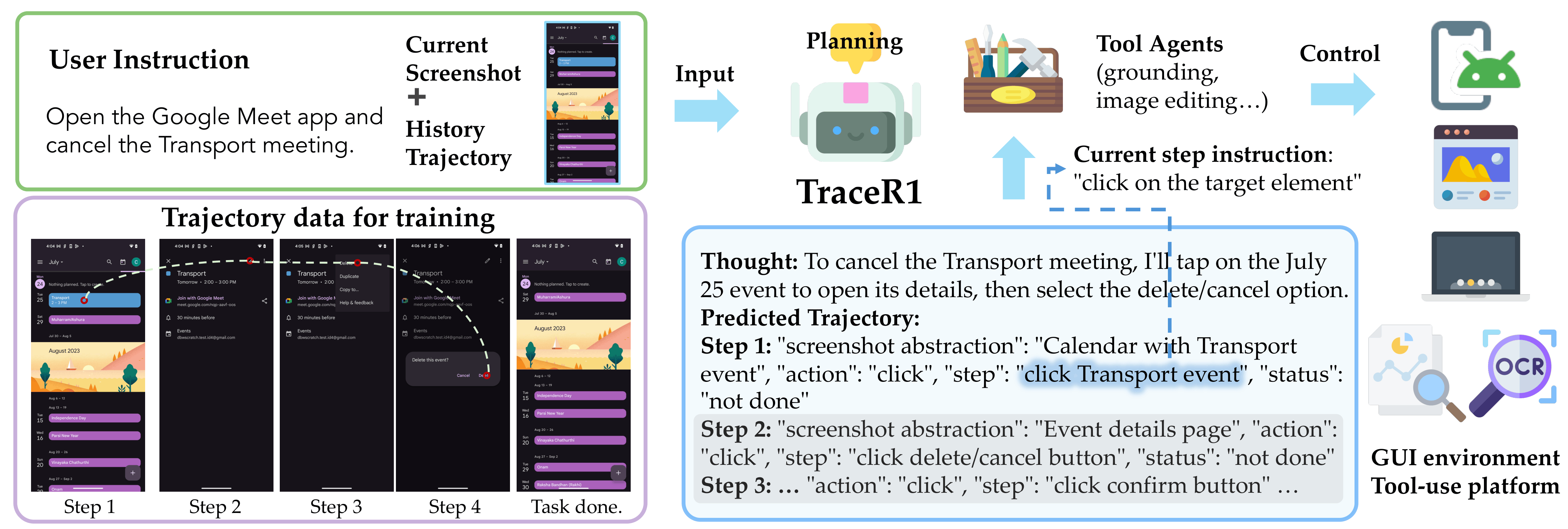
The bottlenecks of action as interface are real, and they are structurally different from those of code. The most fundamental is that action models learn in a world they simultaneously change. In language modeling, a wrong token does not alter the next sentence; in physical manipulation, a wrong grasp changes the scene for every action that follows. This makes compounding errors not just an engineering nuisance but a consequence of the learning paradigm itself. Generalization is bounded by the training distribution: when instructions or object configurations deviate from what the model has seen, performance degrades in ways that code agents, which synthesize new programs from new instructions, do not face. And long-horizon planning remains weak, in part because action models lack persistent memory. Code maintains state through variables and control flow; action models compress everything into a fixed context window, with no mechanism to accumulate experience across steps, remember what has been tried, or track how the environment has changed over time.
Virtual and Physical: Shared Lessons and Open Gaps
What does transfer between virtual and physical agents is spatial and temporal reasoning. The ability to perceive where things are in space and anticipate how they will move shows up in both worlds, though in different forms: as visual trajectory prediction over video in physical manipulation15, and as future action sequence prediction in GUI environments16. These are not surface-level analogies. The same underlying capacities, grounding actions in spatial structure and building expectations of the future before committing, carry across domains. This is among the strongest evidence so far that virtual and physical agents can share deep cognitive structure, not just architecture.
Making vibe agents reliable in the physical world is the central challenge. Scaffolding simplifies what the agent reasons about; harness is what keeps it on track when things go wrong. In the physical world, both remain underdeveloped. Neither substitutes for the other. Scaffolding without a harness produces brittle agents that look capable until conditions shift. A harness without scaffolding forces the agent to reinvent low-level utilities from scratch on every task.
The harness playbook from software extends to the physical world, but the loop is far from closed. Software harnesses rely on deterministic feedback, static environments, and constraints that can be enforced before violations occur. The physical world offers none of these. Feedback is noisy, environments shift mid-task, and constraint violations can only be observed after the fact. Harness engineering in software has converged on concrete practices: how to structure context, impose architectural constraints, and manage entropy over time4. The physical world raises analogous questions. How should tasks be decomposed when the environment is continuous and partially observable? How should state be tracked across steps? How should completion be verified when success is a judgment over noisy sensors, not a binary test? And how should the system recover when a failure has already physically occurred? Neither interface has answered them well yet.
Final Remarks
In an era where vibe agents have already transformed how we work, the natural next question is whether they can do the same for the physical world. But if there is one thing the physical world makes clear, it is that capability without a closed loop is just a demo. The hybrid pattern in code and action as interfaces is emerging in both worlds, but the harness that makes it reliable in the physical world does not yet exist. The vibes are here. Gravity is waiting.